Docker
Вопросы по контейнеризации и Docker
Вопрос 1
## Есть ли разница?
В типичном Dockerfile почти всегда будут присутствовать две группы команд:
- Перенести все нужные файлы внутрь образа
- Установить зависимости
Есть ли разница, в каком порядке эти группы команд располагать друг относительно друга (выше или ниже) в Dockerfile?
Ответ
## Есть!
Рассмотрим пример:
```dockerfile
...
COPY . .
RUN pip install --no-cache-dir -r requirements.txt
...
```
Пусть мы ведём локальную разработку. Значит, мы часто меняем код и собираем наш образ. Зависимости меняются сильно реже кода.
При изменении кода и пересборке образа установка зависимостей запустится заново. Это увеличит время сборки и добавит дискомфорта в разработку.
Дело в том, что `COPY` изменит слой, следовательно, кеш следующих слоёв станет неактуальным, и их нужно будет собрать заново.
**Решение** — реструктурировать Dockerfile: поставить установку зависимостей перед копированием кода:
```dockerfile
...
COPY requirements.txt requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
...
```
В таком случае изменения только в коде не повлекут за собой установку библиотек, т.к. слой с установкой docker возьмёт из кэша.
Вопрос 2
## Тренировка модели
Пусть у нас есть образ `trainer-image:latest`, в котором происходит тренировка DL-модели на pytorch. Какие проблемы может таить в себе такой запуск?
```bash
docker run trainer-image:latest
```
Ответ
## Тренировка модели
```bash
docker run trainer-image:latest
```
1. **Во-первых**, наш запуск захватит собой терминал и обычно лучше запускать процесс в демоне при помощи флага `-d`
2. **Результат тренировки** — это какие-то артефакты. Например, чекпоинт модели. А Docker-контейнеры эфемерны, т.е. после конца тренировки всё, что сохранялось в контейнере, будет удалено. Поэтому нужно добавить volume: `-v /path/to/local/dir:/dir/in/container`. Если вы сохраняете все артефакты на удалённом хранилище при помощи, например, dvc, clearml, wandb и т.п. и вас не страшит эфемерность контейнера, то вы всё делаете правильно.
3. **Секреты.** Если артефакты сохраняются при помощи систем по типу clearml или mlflow, то они обычно требуют секретов (пароли, access/secret-ключи для s3 и т.п.). В нашем примере всё будет работать только если эти секреты уже находятся внутри образа, а это не очень хорошо. Можно передать нужные секреты через переменные окружения `-e S3_ACCESS_KEY=…` или примонтировать файлик с ними: `-v ./secret_config.yml:/app/config.yml`. Также можно использовать специальные сервисы, например, [vault](https://developer.hashicorp.com/vault).
4. **GPU.** Если мы тренируем модель на gpu, то нужно не забыть их прокинуть: `--gpus '"device=0,1"'` — если хотим, чтоб было видно 0 и 1 карточки, `--gpus all` — чтобы было видно все. Также бывает полезно контролировать оперативную память и cpu: параметры `--memory` и `--cpu`.
5. **`--shm-size`.** Shm (shared memory) — общая память между процессами. Когда мы используем, например, DataLoader из PyTorch, данные загружаются не одним процессом, а несколькими воркерами. Чтобы данными мог воспользоваться главный процесс, воркеры записывают их в общую память. Если размер `--shm-size` слишком маленький (по умолчанию всего 64 мб), то могут происходить разные спецэффекты: тормозить сбор батча, фризы, ошибки. Обычно этот параметр лучше сделать побольше, например, `--shm-size=1g`.
Вопрос 3
## Ничего не забыли?
Посмотрим на строчку в Dockerfile:
```dockerfile
...
RUN pip install -r requirements.txt
...
```
Гарантируется, что файл `requirements.txt` есть в образе, версии зафиксированы и все библиотеки установятся без конфликтов. Есть ли тогда проблемы в этой строчке?
Ответ
## Кеши
Пакетные менеджеры по умолчанию предполагают, что их вызывают обычные пользователи на обычном компьютере. Поэтому они стараются сделать так, чтобы одни и те же пакеты/библиотеки не нужно было заново скачивать, компилировать, устанавливать и т.п. Для этого они складывают всё полезное в кеши: чтобы при повторной установке `torch` пользователю не нужно было ждать, пока скачается 2 гигабайта файлов.
Для приложений с лёгкими зависимостями кеш не так заметен, но в DL может спокойно оказаться, что на 4 gb библиотек приходится 2 gb кеша.
Но в Docker нам не нужно такое поведение. Docker-контейнеры по своему замыслу эфемерны и в них мы «повторно» не устанавливаем библиотеки. Поэтому кеш нам не нужен и мы можем значимо облегчить наш Docker-образ. В некоторых пакетных менеджерах есть флаги, которые его отключат:
```dockerfile
RUN pip install --no-cache-dir -r requirements.txt
```
Но не во всех пакетных менеджерах есть такой флаг. В таком случае подчищаем сами:
```dockerfile
RUN apt-get update \
&& apt-get install -y --no-install-recommends \
<smth_libs> \
&& rm -rf /var/lib/apt/lists/*
```
Вопрос 4
## Устанавливаем
Посмотрим на строчку в Dockerfile. Всё ли с ней хорошо?
```dockerfile
...
RUN apt-get update && \
apt-get install python3 python3-pip && \
rm -rf /var/lib/apt/lists/*
...
```
Ответ
Сборка образа либо зависнет, либо упадёт с ошибкой. `apt-get install` запускается в интерактивном режиме и будет спрашивать вашего согласия на установку пакетов (введите Y/n). Сборка образа проходит в неинтерактивной среде, поэтому установить пакеты не получится.
Поэтому нужно добавить флаг `-y` — «да, мы со всем согласны заранее, python в 300мб нас не пугает».
```dockerfile
...
RUN apt-get update && \
apt-get install -y python3 python3-pip && \
rm -rf /var/lib/apt/lists/*
...
```
Вопрос 5
## Как добавить модель?
Пусть мы натренировали нейросеть, сконвертировали её в нужный формат и хотим, чтобы наш сервис её использовал внутри docker. Какими способами можно этого добиться?
Ответ
## Как добавить модель?
**1. Скачивание при инициализации.** Можно при инициализации сервиса скачивать нужный чекпоинт. Это первый вариант, но не очень хороший. Приятно работать с контейнерами, которые быстро стартуют. Если модель весит много, возникают проблемы с сетью — контейнер уже запустился, но обрабатывать трафик ещё не готов. С этим можно работать (см. [probes](https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/) в k8s), но при любом перезапуске нужно заново качать и ждать.
**2. COPY в образ.** Просто добавим модель в docker-образ:
```dockerfile
...
COPY model.format /models/model.format
...
```
Теперь мы не ждём скачивания при старте. Но в случае больших моделей образы станут слишком «толстыми». Можно использовать базовый образ с моделью.
**3. Init-контейнеры.** Если модель находится рядом, можно пробросить через volume. «Разнесём» скачивание и сервис на два контейнера: первый скачивает модель в общий volume, второй использует её.
```yaml
version: "3.8"
services:
model-inference:
build:
context: .
dockerfile: Dockerfile
target: prod
depends_on:
download-model:
condition: service_completed_successfully
ports:
- 8000:8000
volumes:
- model:/app/ro
download-model:
build:
context: .
dockerfile: Dockerfile
target: model-downloader
args:
- FILE_SERVER_URL=<model_url>
volumes:
- model:/app/rw
volumes:
model:
```
Аналогичный подход можно применить и в k8s с помощью [init-контейнеров](https://kubernetes.io/docs/concepts/workloads/pods/init-containers/).
Вопрос 6
## Ищем ошибки
Делаем сервис, которым будут пользоваться как приложением в браузере. Посмотрите на этот docker-compose. Всё ли с ним хорошо?
```yaml
version: "3.9"
services:
frontend:
build: ./frontend
ports:
- "80:3000"
backend:
build: ./backend
ports:
- "5000:5000"
depends_on:
- frontend
db:
image: postgres:15
ports:
- "5432:5432"
depends_on:
- frontend
```
Ответ
## Ищем ошибки
**1. Сервисы неправильно зависят друг от друга.** Первой должна «ожить» база. База не должна зависеть ни от бекенда ни от фронтенда. Бекенд не сможет работать без базы, поэтому `depends_on: db`. Фронтенд не сможет жить без бекенда: `depends_on: backend`.
**2. «Торчащие» порты.** Мы ожидаем, что пользователи взаимодействуют только с фронтендом. Не нужно открывать доступ до бекенда и базы из внешнего мира. Убираем `ports` из backend и db.
**3. Docker-контейнеры эфемерны.** Базы данных — statefull приложения. Перезапуск не должен означать очистку базы. Нужно добавить volume.
Исправленный вариант:
```yaml
version: "3.9"
services:
frontend:
build: ./frontend
ports:
- "80:3000"
depends_on:
- backend
backend:
build: ./backend
depends_on:
- db
db:
image: postgres:15
volumes:
- db_data:/var/lib/postgresql/data
volumes:
db_data:
```
Вопрос 7
## Образ поменьше
Расскажите про подходы, которые помогают сделать docker-образ поменьше.
Ответ
## Образ поменьше
**1. Выбрать базовый образ поменьше.** Например, вместо `python:3.11` (390 мб) выбрать `python:3.11-slim` (45 мб). Но не советуем спускаться до совсем минимальных базовых образов — может возникнуть слишком много проблем с установкой системных библиотек.
**2. Не тянуть лишнего.** После сборки образа можете провалиться в контейнер и посмотреть, нет ли чего-то лишнего: venv с вашего ПК, `.git`, бинари. Лучше явно копировать только то, что нужно, и не забывать про `.dockerignore`.
**3. Нам не нужны кеши.** Для установки библиотек часто сохраняются кеши. Не забывайте их отключать:
```dockerfile
RUN pip install --no-cache-dir -r requirements.txt
```
И для apt-get:
```dockerfile
RUN apt-get update && apt-get install -y <libs> && rm -rf /var/lib/apt/lists/*
```
**4. Multi-stage сборки.** Можно сделать builder-образ для сборки, а затем перетащить в образ-результат только нужные файлы. [Отличный пример](https://docs.docker.com/build/building/multi-stage/) есть в документации docker.
Вопрос 8
## Устанавливаем apt-get'ом
Всё ли хорошо с этими командами?
```dockerfile
RUN apt-get update
RUN apt-get install -y curl
```
Ответ
## Устанавливаем apt-get'ом
`apt-get update` обновляет индексы пакетов. Если слой с `update` возьмётся из кэша, а репозитории уже изменились, `apt-get install` может не найти пакеты или поставить не то.
Правильнее объединить эти команды в одну и в конце не забыть прибраться:
```dockerfile
RUN apt-get update \
&& apt-get install -y --no-install-recommends curl \
&& rm -rf /var/lib/apt/lists/*
```
Вопрос 9
## Почему так долго?
Сборка простого образа занимает неожиданно много времени. В логах видно:
```
Sending build context to Docker daemon 25GB
```
Хотя весь код весит 2 MB. В чём причина?
Ответ
## Build context
При `docker build .` docker отправляет демону весь контент текущей директории. Типичные «тяжёлые» вещи, которые случайно попадают в контекст:
- `.git/` (может быть огромным)
- `venv/`
- Датасеты, чекпоинты моделей
- Логи, временные файлы
Не забывайте всё тяжёлое и локальное «спрятать» при помощи `.dockerignore`, который сработает аналогично `.gitignore`, но для docker.
Вопрос 10
## Selective builds
Пусть в нашем монорепозитории есть несколько сервисов:
```
repo/
├── services/
│ ├── api/
│ ├── worker/
│ └── dl/
└── shared/
```
В CI мы не хотим собирать образы и пушить их в registry для каждого из сервисов при каждом коммите. Хотим собирать только для тех, где были изменения. Как такое реализовать?
Ответ
## Selective builds
Например, в GitlabCI это можно сделать при помощи `rules`:
```yaml
build-api:
rules:
- changes:
- services/api/**/*
- shared/**/*
script:
- docker build ...
build-worker:
rules:
- changes:
- services/worker/**/*
- shared/**/*
script:
- docker build ...
```
В таком случае, если в файлах сервиса и общих файлах ничего не было изменено, то и образ не будет пересобираться.
Вопрос 11
## Виртуализация vs Контейнеризация
Расскажите «на пальцах», чем виртуализация отличается от контейнеризации?
Ответ
## Виртуализация vs Контейнеризация
### Виртуализация
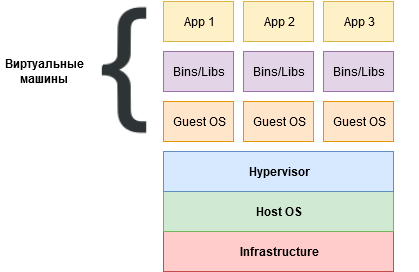
Снизу — физическое железо сервера. Дальше может быть гипервизор (иногда ставится прямо на железо, иногда поверх хостовой ОС). Гипервизор управляет виртуальными машинами — изолированными окружениями с виртуальными CPU/памятью/дисками/сетью, в которых запускаются гостевые операционные системы.
### Контейнеризация
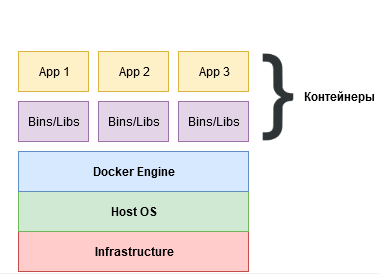
Снизу железо и хостовая система. Далее Docker Engine — клиент-серверное приложение для запуска и управления контейнерами.
**Контейнер** — изолированный процесс с приложением и всеми зависимостями. Контейнеры легковеснее виртуальных машин, потому что используют ядро хостовой ОС (не поднимают отдельную гостевую ОС), поэтому запускаются заметно быстрее.
> ⚠️ Из-за зависимости от хостовой ОС контейнер, подготовленный под одну ОС, не факт, что заработает на другой. Но чаще всего это не проблема — почти все на Unix-подобных ОС.
### Основное отличие
В виртуализации мы поддерживаем ресурсами целую ОС. При контейнеризации всё делается на хостовой ОС — экономия ресурсов и скорость, но страдает изоляция.
Контейнеры подходят, когда:
1. Хотим быстро развернуть без накладных расходов
2. Не критична зависимость от хостовой ОС
Вопрос 12
## Как идея?
Хорошая ли идея засовывать внутрь docker-контейнера сразу несколько работающих приложений (процессов)?
Ответ
## Как идея?
Зачастую это будет **плохой идеей**. Правило «один Docker-контейнер — один процесс» не закон, но на практике почти всегда полезно им пользоваться.
Почему один процесс обычно лучше:
- **Масштабирование:** захочется увеличить только количество воркеров — придётся масштабировать вместе со всем остальным
- **Надёжность:** если упал один из процессов, docker может посчитать упавшим «всё сразу» (если повезло), либо приложение будет жить с «сломанной» частью — с точки зрения docker если PID 1 жив, всё в порядке
- **Сигналы** (SIGTERM, SIGKILL) доставляются только главному процессу с PID 1, дочерние могут не завершиться корректно
- **Наблюдаемость:** логи, метрики, healthcheck'и — всё проще, когда один процесс
- **Обновления:** чтобы обновить одно приложение, нужно пересобирать и перезапускать весь контейнер
Вопрос 13
## Restart policies
Чем отличаются эти политики перезапуска?
```bash
docker run --restart=no ...
docker run --restart=always ...
docker run --restart=unless-stopped ...
docker run --restart=on-failure:5 ...
```
Ответ
## Restart policies
- **no** (по умолчанию): не перезапускать никогда
- **always**: перезапускать всегда, даже если контейнер остановлен вручную. После перезагрузки docker daemon тоже его перезапустит
- **unless-stopped**: как always, но если контейнер был остановлен вручную, то до перезагрузки daemon'а не запустится автоматически
- **on-failure[:max-retries]**: перезапускать только при ненулевом exit code. Можно ограничить число попыток
Вопрос 14
## Multi-stage
Расскажите про multi-stage сборку и напишите пример Dockerfile с ней.
Ответ
## Multi-stage
Multi-stage сборка позволяет использовать несколько команд `FROM` в одном Dockerfile. Каждый `FROM` начинает новый этап (stage), и в финальный образ можно скопировать только нужные артефакты из предыдущих этапов.
Для сборки часто нужны компиляторы, SDK, dev-зависимости, исходники. Но для запуска нужен только готовый бинарник/артефакт.
Пример из [документации](https://docs.docker.com/build/building/multi-stage/#name-your-build-stages) docker:
```dockerfile
# сборка
FROM golang:1.24 AS build
WORKDIR /src
COPY <<EOF /src/main.go
package main
import "fmt"
func main() { fmt.Println("hello, world") }
EOF
RUN go build -o /bin/hello ./main.go
# в финальный образ только бинарник
FROM scratch
COPY --from=build /bin/hello /bin/hello
CMD ["/bin/hello"]
```
Multi-stage особенно «полюбилась» в компилируемых языках. В Python тоже можно найти применение, например, разделение dev и prod зависимостей:
```dockerfile
FROM python:3.12 as prod
WORKDIR /app
RUN apt update && apt install -y curl && rm -rf /var/lib/apt/lists/*
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY main.py .
CMD python main.py
FROM prod as dev
COPY requirements.dev.txt .
RUN pip install --no-cache-dir -r requirements.dev.txt
```
Вопрос 15
## Устанавливаем зависимости
У приложения есть два вида зависимостей: лёгкие, которые к тому же часто меняются. И тяжёлые — pytorch и т. п., которые меняются редко. Всё ли хорошо мы делаем в этом Dockerfile?
```dockerfile
...
COPY light-requirements.txt heavy-requirements.txt ./
RUN pip install --no-cache-dir -r light-requirements.txt -r heavy-requirements.txt
...
```
Ответ
## Устанавливаем зависимости
Сейчас если изменились `light-requirements.txt`, то это инвалидирует слой `COPY …` и все слои ниже него. А значит, при изменении «лёгких» зависимостей мы будем также вынуждены переустановить и «тяжёлые».
Чтобы при изменении лёгких зависимостей нужно было переустанавливать только их:
```dockerfile
...
COPY heavy-requirements.txt .
RUN pip install --no-cache-dir -r heavy-requirements.txt
COPY light-requirements.txt .
RUN pip install --no-cache-dir -r light-requirements.txt
...
```
Теперь слой с тяжёлыми зависимостями стоит выше слоя с лёгкими и не будет инвалидироваться при изменении `light-requirements.txt`.