LLM 2
Вопросы про LLM часть 2
Вопрос 1
# Padding mask и causal mask
Как работают padding-маска и causal-маска в механизме внимания трансформера?
Ответ
## Ответ
Обе маски применяются к логитам внимания $QK^T$ до $softmax$ (обычно добавлением $-\infty$ или $-1e9$).
### Padding mask
- Нужна, потому что последовательности разной длины дополняют `PAD`-токенами
- Маска обнуляет внимание к PAD-позициям: `scores[pad] += -1e9` $\rightarrow$ после $softmax$ вес $\approx 0 $
- Используется и в энкодере, и в декодере
- На практике стараются минимизировать паддинг (bucketing/packing), чтобы не тратить вычисления
### Causal (autoregressive) mask
- Нужна в декодере: токен на позиции $i$ не должен видеть позиции $i+1, i+2, ...$
- Реализуется как верхнетреугольная маска: элементы выше диагонали получают $-\infty$ до $softmax$
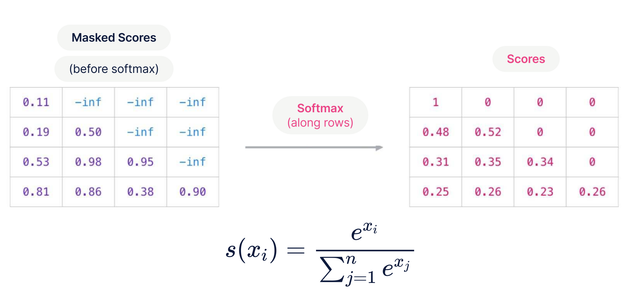
- После $softmax$ веса «в будущее» становятся нулевыми $\rightarrow$ внимание идёт только влево
Вопрос 2
# Residual connections
Зачем нужны residual connections (skip-connections) в трансформере?
Ответ
## Ответ
Проблема глубоких сетей: градиенты могут затухать при обратном распространении.
**Residual connection:** $output(x) = x + F(x)$
Производная: $\frac{\partial \, output(x)}{\partial x} = 1 + \frac{\partial F}{\partial x}$. Слагаемое $+1$ даёт «прямой путь» градиента, улучшая обучение глубоких моделей.
В современных LLM часто используют pre-norm вариант:
- `x = x + SelfAttention(LayerNorm(x))`
- `x = x + FFN(LayerNorm(x))`
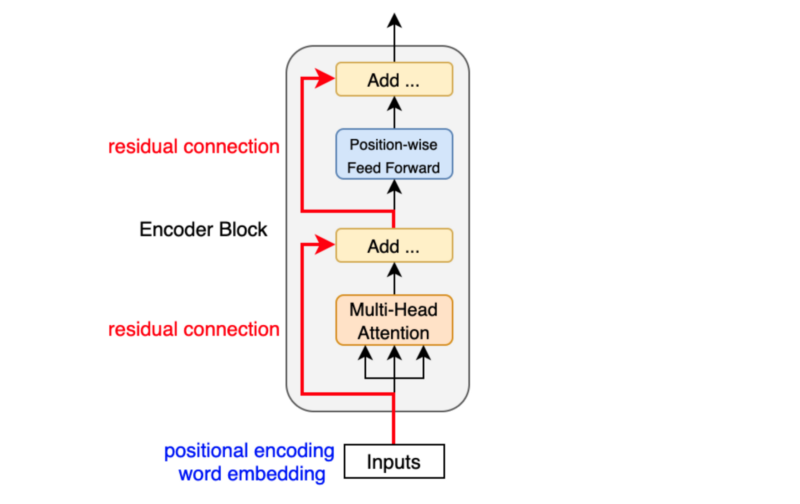
Дополнительно residual-путь помогает учить остаточную поправку к входу, что часто проще, чем строить представление с нуля.
Вопрос 3
# Multi-Head Attention
Зачем нужен Multi-Head Attention и как он работает?
Ответ
## Ответ
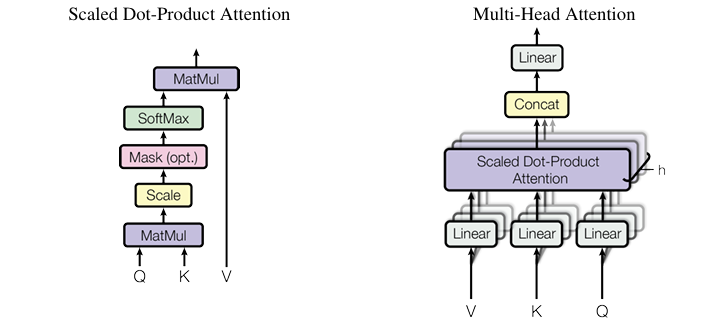
Одна голова attention ограничена: она учит один «способ смотреть» на контекст.
**Multi-Head Attention** запускает несколько голов параллельно:
- у каждой головы свои матрицы $W_q, W_k, W_v$ (обычно меньшей размерности)
- головы могут специализироваться на разных отношениях (синтаксис, семантика, кореференция и т.д.
- выходы голов конкатенируются и проходят через итоговую линейную проекцию
Вопрос 4
# Позиционные эмбеддинги
Зачем в трансформере нужны позиционные эмбеддинги?
Ответ
## Ответ
Self-attention сам по себе не кодирует порядок токенов: операция симметрична относительно перестановки позиций. Без позиционных эмбеддингов «dog bites man» и «man bites dog» дадут одинаковые представления.
Чтобы модель знала порядок, добавляют позиционную информацию:
- Абсолютные (классический трансформер): синус/косинус от позиции (необучаемые)
- Обучаемые абсолютные: отдельный обучаемый вектор на каждую позицию
- Относительные (например, RoPE): позиционная информация вшивается в attention так, что модель лучше переносится на новые длины контекста
Вопрос 5
# GQA
Что такое GQA (Grouped Query Attention) и зачем он нужен?
Ответ
## Ответ
В обычном multi-head attention у каждой головы свои $K$ и $V$, поэтому KV-cache растёт как размерность головы $\times$ число голов $\times$ длина контекста.
Альтернативы:
- MQA (Multi-Query Attention): все головы имеют разные $Q$, но делят одну пару $K, V$ $\rightarrow$ минимальный KV-cache, иногда хуже качество
- GQA (Grouped Query Attention): головы $Q$ разбиваются на $G$ групп, и каждая группа делит свои $K, V$ $\rightarrow$ компромисс между MHA и MQA
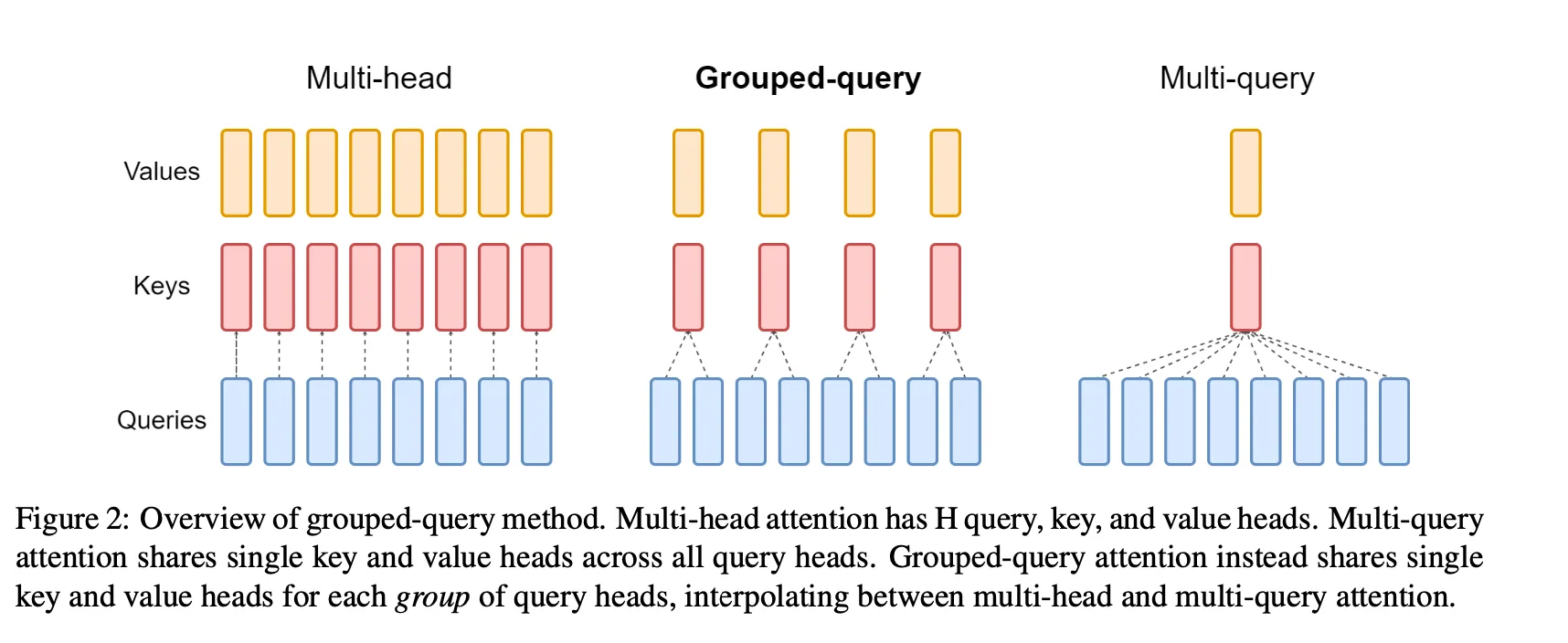
Пределы:
- `G = 1` → MQA
- `G = #heads` → MHA
GQA используется во многих современных моделях (например, в семействе LLaMA и др.).
Вопрос 6
# Scaling laws
Что такое scaling laws в LLM и как они влияют на выбор размера модели?
Ответ
## Ответ
**Scaling laws** — эмпирические законы, связывающие качество LLM с:
- размером модели $N$ (число параметров)
- объёмом данных $D$
- бюджетом вычислений $C$
Практический вывод из Chinchilla-подобных законов: при фиксированном бюджете вычислений часто выгоднее обучать не слишком большую модель на большем объёме данных, чем наоборот.
Грубое правило для плотных моделей: порядка **~20 обучающих токенов на 1 параметр** (масштабный ориентир, не «закон природы»).
Вопрос 7
# Этапы от случайных весов до ассистента
Какие этапы обучения проходят современные модели от случайных весов до готового ассистента?
Ответ
## Ответ
Типичный пайплайн:
1. **Pretraining** — обучение на огромном корпусе (интернет-тексты и т.п.) в задаче next-token prediction. Базовая модель хорошо продолжает текст и усваивает знания/паттерны
2. **SFT (Supervised Fine-Tuning)** — дообучение на примерах «инструкция → ответ» (диалоги, форматирование, стиль). Модель становится «instruction-following»
3. **Alignment** (семейство методов) — настройка поведения: полезность, безопасность, отказ от вредного контента, предпочтения пользователя. Примеры: RLHF, DPO, KTO, RLAIF/Constitutional AI
Вопрос 8
# FSDP vs DDP
Что такое FSDP (PyTorch) и чем он отличается от DDP?
Ответ
## Ответ
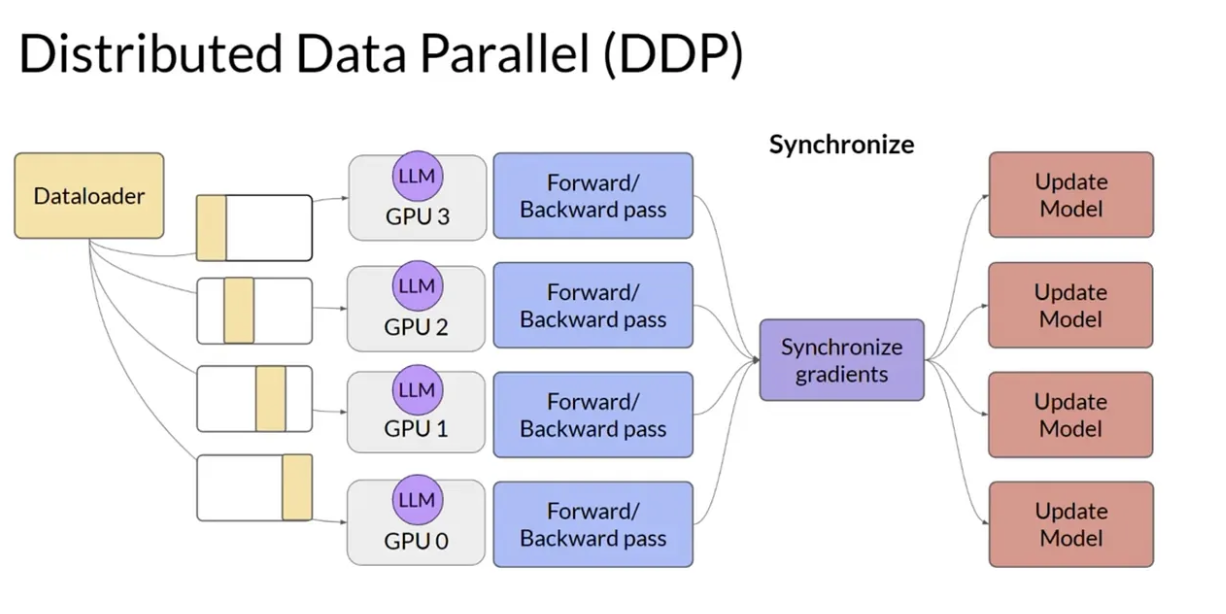
**DDP (DistributedDataParallel):**
- на каждом GPU хранится полная копия параметров модели
- градиенты синхронизируются через `all-reduce`
- просто и эффективно, но очень затратно по памяти
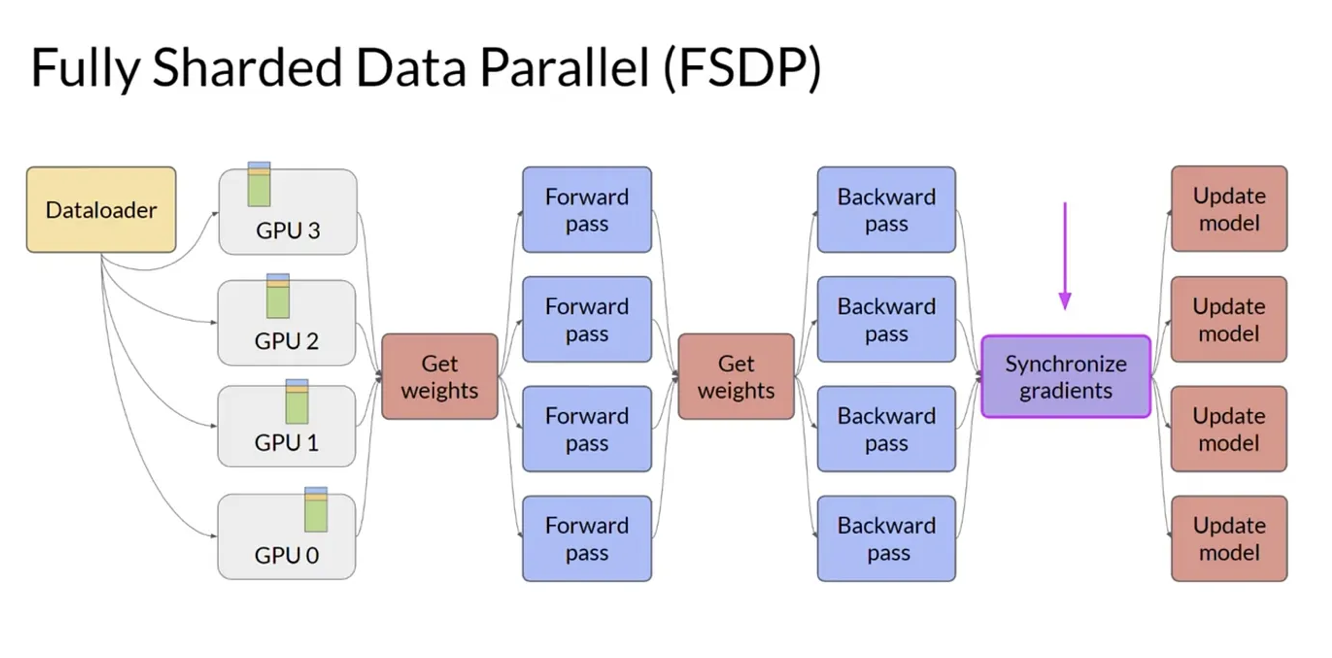
**FSDP (Fully Sharded Data Parallel):**
- шардирует состояние обучения между GPU, уменьшая дублирование
Режимы:
- NO_SHARD — по сути как DDP
- SHARD_GRAD_OP — шардируются градиенты и состояния оптимизатора
- FULL_SHARD — шардируются параметры + градиенты + оптимизатор
Картинки взяты из отличного [поста](https://medium.com/@yashdoza21/scaling-model-training-across-multiple-gpus-efficient-strategies-with-pytorch-ddp-and-fsdp-d744be462667).
Вопрос 9
# Perplexity
Что такое перплексия (perplexity) и как её интерпретировать?
Ответ
## Ответ
**Perplexity (PPL)** измеряет, насколько модель «удивлена» текстом.
$PPL = exp( - \frac{1}{N} · \sum \limits_{i}^{N} log P(t_i | t_{<i}) )$
То есть: `PPL = exp(cross-entropy loss)`.
Интуиция: $PPL = 100$ примерно значит, что в среднем модель ведёт себя как будто выбирает следующий токен из ~100 равновероятных вариантов.
Ограничения:
- зависит от токенизатора (нельзя напрямую сравнивать PPL между разными токенизаторами)
- не всегда идеально коррелирует с downstream-качеством
Вопрос 10
# Параллелизмы
Что такое DDP, pipeline и tensor parallelism? Когда что использовать?
Ответ
## Ответ
Три базовых подхода к распределённому обучению:
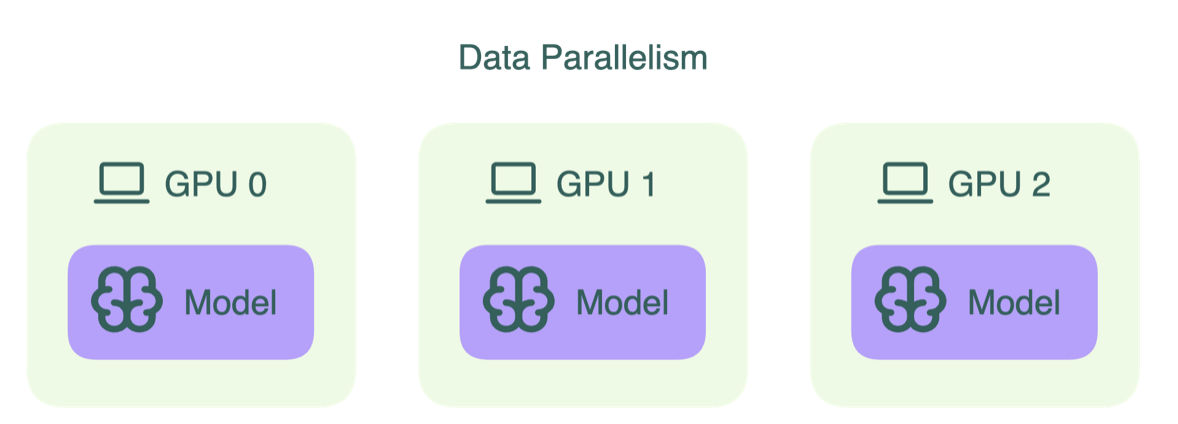
- **DDP (data parallelism):** на каждой GPU полная копия модели, батч делится между GPU, градиенты синхронизируются `all-reduce`.
Плюс: просто и эффективно. Минус: если модель не помещается на одну GPU — DDP не спасает
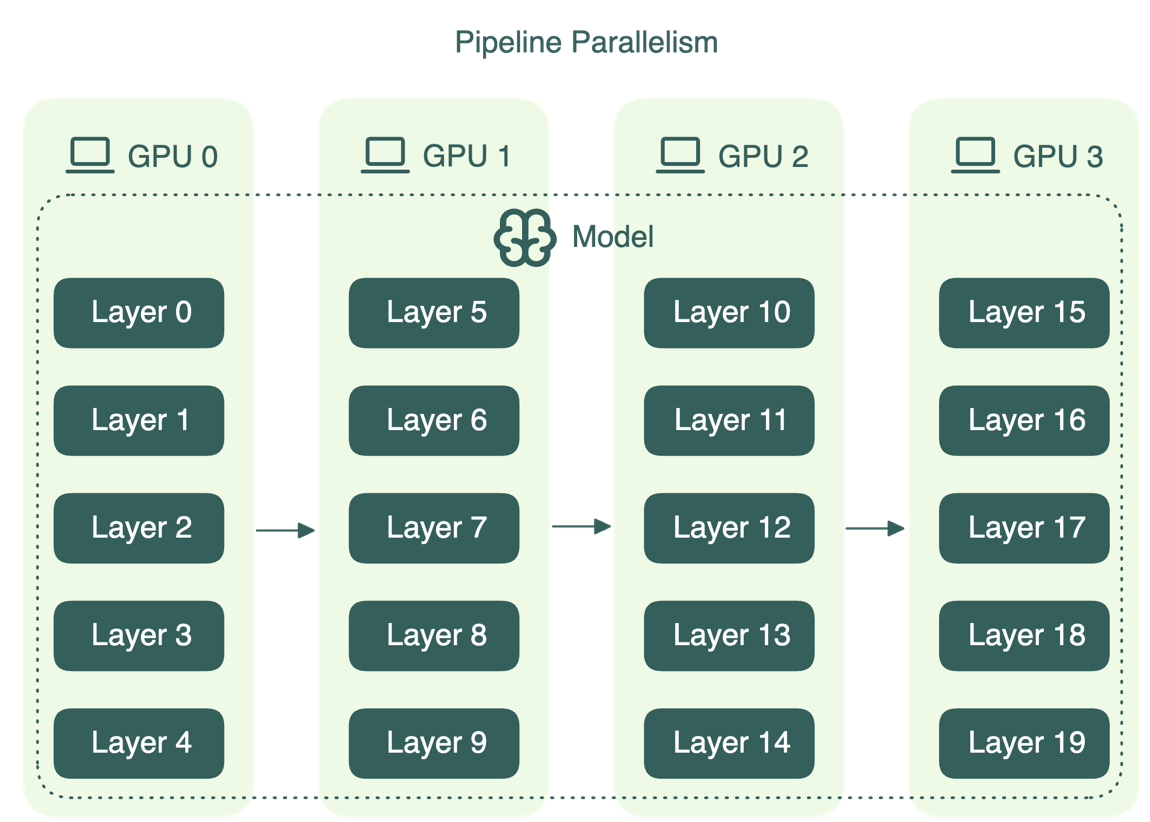
- **Pipeline parallelism:** модель режется по слоям между GPU.
Плюс: можно уместить более крупную модель. Минусы: сложнее реализация и есть «пузырь» простоя
- **Tensor (model) parallelism:** матричные операции режутся вширь (строки/столбцы матриц распределяются по GPU).
Плюс: можно уместить даже «слишком большой слой». Минус: больше коммуникаций
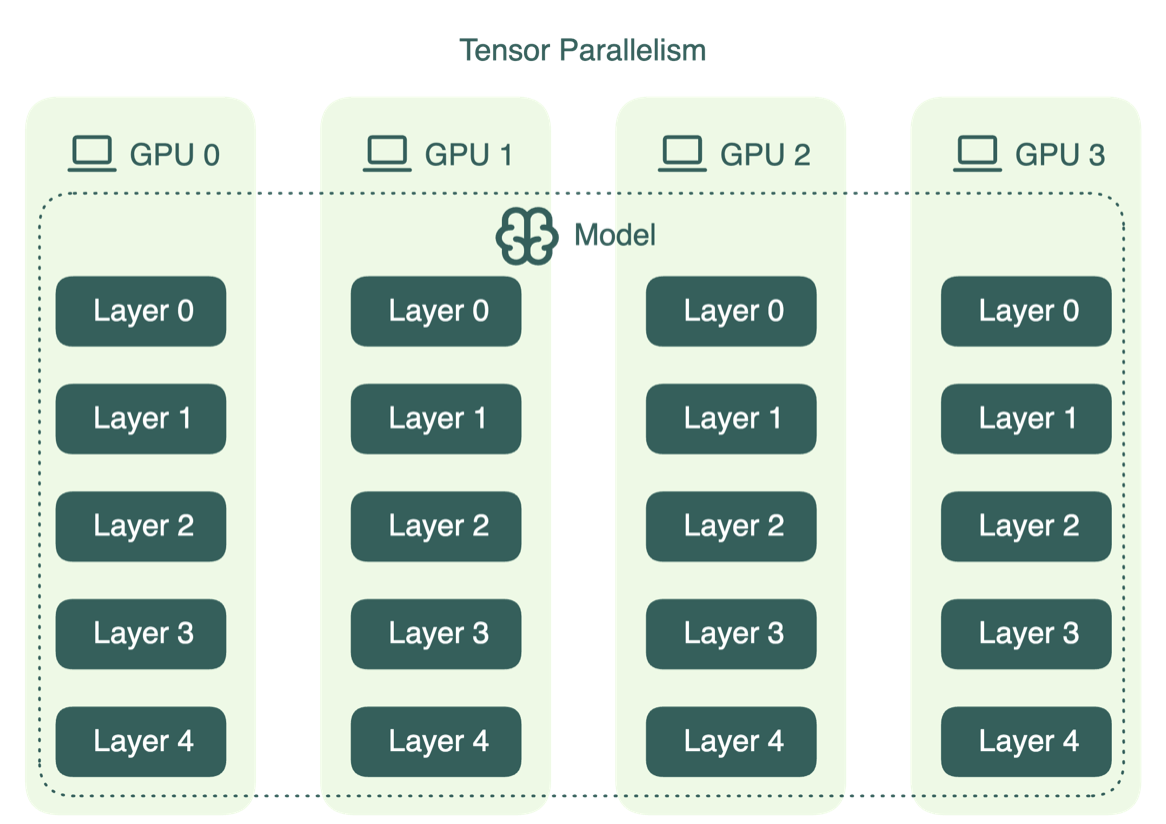
На практике большие модели часто обучают комбинацией (3D-параллелизм).
Картинки взяты из [поста](https://bentoml.com/llm/inference-optimization/data-tensor-pipeline-expert-hybrid-parallelism).
Вопрос 11
## Проблема роста длины ответа в DPO
Что такое проблема роста длины ответа в DPO и как с ней борются?
Ответ
## Ответ
При обучении DPO (и в целом preference/RL-методах) модель может «хакнуть» сигнал предпочтений: делать ответы длиннее, потому что разметчики/оценщики статистически чаще предпочитают более подробные ответы — даже если они менее по делу.
Симптомы:
- ответы становятся избыточно длинными
- метрики/скоры chosen vs rejected сближаются из-за слабой дискриминации качества и доминирования длины
Способы борьбы:
- штраф за длину (length penalty) или нормализация reward по длине
- методы, специально учитывающие длину (например, SimPO)
- альтернативные схемы предпочтений (например, KTO/ORPO) могут быть менее чувствительны к этому артефакту
Вопрос 12
## DPO
Сколько моделей нужно держать в памяти при DPO и в чём его отличие от RLHF?
Ответ
## Ответ
При DPO обычно нужны 2 модели:
1. обучаемая $\pi_{\theta}$
2. референсная (замороженная) $\pi_{ref}$
**Reward Model не нужна**: DPO напрямую обучается на парных предпочтениях `(x, y_win, y_lose)` и увеличивает вероятность предпочтительного ответа относительно референса.
Вопрос 13
## Компоненты RAG
Из каких компонентов состоит RAG-система?
Ответ
## Ответ
RAG обычно состоит из двух блоков:
1. **Retriever (поиск)**
- Embedder: превращает запрос и документы в векторы
- Vector store: хранит эмбеддинги и быстро находит top-k (FAISS, Qdrant, Pgvector и т.д.)
- (Опционально) Reranker: точнее переранжирует кандидатов, но медленнее
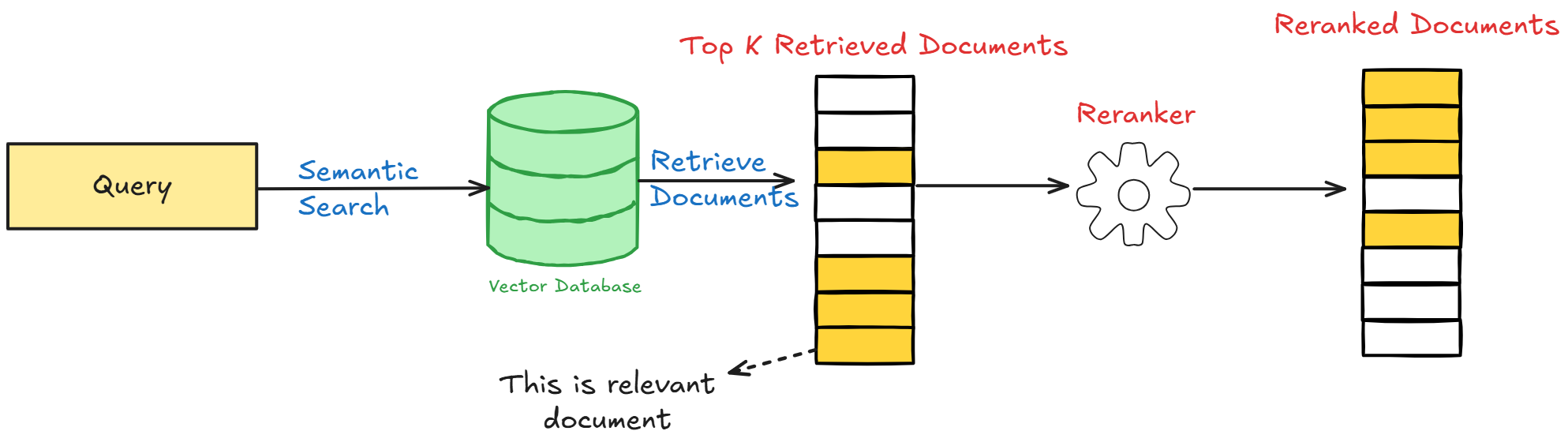
2. **Generator (LLM)**
- получает запрос + найденные фрагменты (чанки) и генерирует ответ, опираясь на них.
Подготовка базы: очистка → нарезка на чанки (часто с перекрытием) → предвычисление эмбеддингов
Вопрос 14
# RAG vs fine-tuning
Когда лучше использовать RAG, а когда fine-tuning?
Ответ
## Ответ
**RAG лучше, когда:**
- знания часто меняются (документация, прайсы, новости)
- нужны персональные/закрытые данные без вшивания в веса
- важны источники и проверяемость (можно показывать документы)
**Fine-tuning лучше, когда:**
- нужно поменять стиль/формат ответов и устойчиво следовать правилам
- хочется дистиллировать поведение/умения в меньшую модель
- нужно научить специфичному формату/протоколу (например, function calling, структурированный вывод)
Упрощённо: RAG = внешний источник знаний, fine-tuning/alignment = поведение и формат.
Вопрос 15
# Chain-of-Thought
Что такое Chain-of-Thought (CoT) промптинг и почему он работает?
Ответ
## Ответ
**Chain-of-Thought** — техника, где модель побуждают строить промежуточные шаги рассуждения перед ответом (например, через примеры с разбором решения).
Интуиция: авторегрессия позволяет «распределить» сложное рассуждение по нескольким токенам, а промежуточный текст становится контекстом для следующих шагов
Вопрос 16
# LLM-агент
Что такое LLM-агент и из каких компонентов он состоит?
Ответ
## Ответ
LLM-агент — система, где LLM выступает «мозгом», который планирует и вызывает инструменты, наблюдает результаты и повторяет цикл до цели.
Компоненты:
- Reasoning/Planning (например, ReAct)
- Tools (поиск, код, API, калькулятор)
- Memory (краткосрочная история + долгосрочная память, например, векторная БД),
- Reflection/оценка (проверка результата и коррекция плана).
Типичный цикл: Thought → Action → Observation → ... → Answer.
Вопрос 17
# Как изображение попадает в LLM (VLM)
Как работают Vision-Language Models (VLM)? Как изображение попадает в LLM?
Ответ
## Ответ
Типичная схема VLM (например, LLaVA-подобные):
1. Изображение режут на патчи (как в ViT)
2. Visual encoder превращает патчи в последовательность визуальных эмбеддингов
3. Небольшая проекция (MLP / cross-attention) переводит визуальные эмбеддинги в пространство токенов LLM
4. Визуальные «токены» конкатенируют с текстовыми токенами промпта и подают в LLM
Для LLM изображение превращается в дополнительные входные токены.
Вопрос 18
# Галлюцинации
Что такое галлюцинации LLM и почему они возникают?
Ответ
## Ответ
Галлюцинации — когда модель уверенно выдаёт фактически неверную информацию (ошибочные факты, выдуманные ссылки/источники).
Почему возникают:
- обучение оптимизирует правдоподобие и связность текста, а не проверку фактов
- ошибки/устаревание в данных обучения
- запросы вне распределения (модель «додумывает» по аналогии)
- у модели нет встроенного механизма «проверить» факт без внешних инструментов
Вопрос 19
# Dynamic/continuous batching
Что такое динамический (continuous) батчинг и почему он важен для инференса LLM?
Ответ
## Ответ
При классической генерации в батче все запросы «ждут конца самого длинного запроса»: короткие простаивают или работаю вхолостую.
**Continuous batching** (dynamic batching):
- запросы добавляются в текущий батч по мере освобождения слотов
- как только один запрос завершился (EOS/лимит) — на его место ставят новый
- GPU постоянно загружена
Это повышает throughput, особенно когда запросы сильно различаются по длине.
Вопрос 20
# Speculative decoding
Что такое speculative decoding и какое ускорение он даёт?
Ответ
## Ответ
Идея: часть токенов «лёгкие» — их можно быстро предложить маленькой моделью.
Схема:
1. **Draft-модель** быстро генерирует `k` токенов-гипотез [авторегрессионно]
2. **Target-модель** проверяет эти `k` токенов за один forward pass [не авторегрессионно, a.k.a. быстро]
3. При несовпадении выполняют корректирующий шаг, чтобы сохранить правильное распределение
При хорошей согласованности draft и target можно получить заметное ускорение, потому что target-модель делает примерно `~N/k` проходов вместо `N` (плюс накладные расходы).